March 9, 2008
High power darlington array
Posted in: TechWhat's an easy way of driving a ton of LEDs? Unfortunately the the Arduino boards can only sink or source about 40mA on each pin, which is enough to drive a few LEDs at most.
Here's how to drive up to eight LED clusters or other high current device off a single, cheap 18-pin IC with no extra components.
The typical solution to drive higher currents is to use the computer (in our case, an Arduino board) to provide the signal, i.e. small current, to a transistor that bears the brunt of switching the lights. The transistor requires a, say 3Kohm, base current limiting resistor and the collector-emitter line requires a resistor too (which you would've needed with the LED anyway). If you have a number of LED clusters to drive you end up having a fair bit of extra componentry to deal with = more soldering/breadboarding.
It turns out someone's thought of this already and produced a handy IC that contains a bunch of these transistor circuits. The doodad in question is a €1.15 ULN2803A darlington pair array [datasheet]. Page 4 of the datasheet, figure 1a has an example circuit.
How these work: The left side of these chips are the input (pins 1-8) and the right side are the ouputs (pins 10-17). Pin 9 is the ground, pin 18 the common +V. Connect your +5V to your load, e.g. LED cluster + appropriate resistor (e.g. 20ohm for ~8 LEDs), and connect the cathode (-V) end of that circuit to an output pin. The darlington circuit acts as a sink. Here's the circuit,
 |
| From Darlington pairs driving LED clusters |
Each darlington circuit can sink 500mA (peak 600mA) and they can be wired in parallel so e.g. connecting two can drive a 1A load.
The example here is using the included Fade demo sketch with an extra write to another pin to flip one cluster one and off just to demonstrate the circuit doing two things. Note how the LED clusters have a common +V and they source separately into different outputs via the small resistors.
March 8, 2008
Arduino showing multiplexed LED matrix
Posted in: Art, Gadgets, Software, TechTo control any more than 12 LEDs on an Arduino board requires a bit of trickery. The Diecimila with its Atmega168 chip has 14 digital output pins, but you somewhat lose two from the TX/RX serial pins on 0 and 1 leaving just 12 pins. Today I built an LED matrix with 20 lights using nine pins,
The technique is to light row by row, and rely on our persistence of vision effect. Playing around with the delay it seemed like 3ms for a total of 15ms (five rows) was about the point where flicker just started being noticeable.
Geeky detail after the fold...
The software pulls the row pins high one by one while the column pins are set low for every LED to light, sinking the current from the one high row pin. There's a 3ms delay, then the next row pin is brought high and the last one low.
The data for the little animation is a 2D byte array that looks like,
byte PATTERN[][5] = {
/* ... */
{B0111,
B1110,
B1100,
B1000,
B0000,},
/* ... */
};
('B' is a handy prefix for a binary number.)
You can see a diagonal band of 1's there in the early part of the wipe. Each byte's translated into pin writes by looking at the lowest bit in the byte and then shifting right and looking at the next. LOW is on.
void SetColumn(byte pattern) {
for (int i = COL_COUNT-1; i >= 0; i--, pattern >>= 1) {
digitalWrite(COL_PINS[i], pattern & 1 ? LOW : HIGH);
}
}
A "frame" of the display is completed by lighting each row in turn,
void ShowPattern(byte pattern[]) {
int last_row = ROW_COUNT-1;
for (int row = 0; row < ROW_COUNT; last_row = row++) {
digitalWrite(ROW_PINS[row], HIGH);
digitalWrite(ROW_PINS[last_row], LOW);
SetColumn(pattern[row]);
delay(MULTIPLEX_DELAY_MS);
}
}
The main loop draws each frame over and over until a certain amount of time has elapsed and then it goes onto the next one. millis() is a built-in that returns the number of milliseconds since the board was switched on. (This code would fail after about nine hours when the counter resets.)
void loop()
{
for (int pos = 0; pos < PATTERN_SIZE; pos++) {
long start = millis();
while (millis() - start < PATTERN_DELAY_MS) {
ShowPattern(PATTERN[pos]);
}
}
}
Notes
I actually had the circuit the other way around, cycling through column-by-column and the rows programmed in turn with a line of lights. This happened out to make writing patterns awkward so I flipped the orientation which made SetColumn pretty straightforward.
The matrix could've had more lights on it but the breadboard limited width a bit. I was quite proud of the tight wiring under the LEDS.
 |
| From Multiplexed LED Matrix |
This was one of the projects where the bits that seemed like they'd be hard Just Worked and then silly things wasted time, like C mistakes with sizeof.
int ROW_PINS[] = {13, 12, 11, 10, 9};
int COL_PINS[] = {5, 4, 3, 2};
#define ROW_COUNT (sizeof(ROW_PINS)/sizeof(ROW_PINS[0]))
#define COL_COUNT (sizeof(COL_PINS)/sizeof(COL_PINS[0]))
Parameterizing these kinds of things made moving from a 3x4 board to 4x5, flipping the rows & columns, and using different pins trivial. An unfortunate cargo-cult effect in Arduino and Wiring code I've seen is folks not using #define and sizeof.
Some cute enhancements might be to have an array of structs, the struct containing additionally a delay time for each frame. We could also have, rather than 0/1, a wider range of values to indicate brightness. With that, (e.g. Perl/Python scripted) code could generate the animation sequences rapidly flipping frames to give an impression of anti-alias. Unfortunately I have other things to do... (yeah, I made the animations by hand in vi and pasted into the Arduino editor :-))
And finally, a Wiring-based pair of color LED matrixes are used as toilet signs... that change throughout the night [video]. More on this funny project.
March 2, 2008
My first Arduino project
Posted in: Gadgets, Software, Tech, What am I up toI've spent a very pleasant Sunday afternoon playing with an Arduino microcontroller board. After a trip to Maplin I plugged together a little array of assorted LEDs from their "lucky bags" and got hacking.
The Arduino board is fabulous: for an amazingly cheap €22 you get a USB-programmable 16Kb microcontroller with a bunch of digital and analog input and outputs, and the outputs are capable of driving useful things like LEDs. The software's not just free but open source too--and it's decent, with excellent documentation. I'd say from downloading the software and getting my first "hello world" program loaded was about five minutes. It Just Worked™. This might not sound like a big deal, but interfacing to computers has generally been expensive, esoteric, fiddly, and error-prone. The Arduino board is none of these.
The tutorials are great and introduce the important concepts with example circuits and code. In fact, the set of example code is all accessible directly from the Arduino app's main menu, which is a nice touch. (I.e. you don't have to dig around trying to open a file buried on your hard drive.)
So anyway here it is. Eleven LEDs connected to digital pins 0-10, and a 22k linear pot (variable resistor) feeding analog pin 5. The LEDs "chase" up and down with a speed taken from the pot position.

It was fairly painless, at least after an initial scare where programs wouldn't upload,
avrdude: stk500_recv(): programmer is not responding avrdude: stk500_recv(): programmer is not responding
I read all sorts of scary solutions online where folks were reprogramming their bootloaders and other horrors. One Arduino hacker mentioned running the board off an external power supply (rather than rely on USB) during programming as the current draw is apparently higher. This was enough for me to try pull the LED's ground pin out so the lights turned off: Bingo! No problem programming. It became a bit annoying pulling the ground lead out every program: next trip to Maplin I get a switch...
The other issue I had was remembering how C does casting. My function to scale the analog input into a minimum and maximum delay was being simultaneously confused by my code not casting up to a float early enough, and a persistently dodgy connection with the pot.
(The fifth pin/LED didn't seem to light very strongly. Tried different LEDs and lower resistance. Didn't fix it or figure out why it was dim; I'll try a different board soon.)
So what led me to Arduino? The brand new Science Gallery at Trinity College in Dublin is running a programme to introduce high school kids who wouldn't otherwise have had the educational opportunity to do so to learn about electronics. I'm helping out there on Wednesday afternoons, which so far has mostly involved teaching them how to solder, and debugging electronics problems. Where possible I have them learn from my mistakes: my room in my parents' house, for example, was so badly burnt from soldering iron accidents and riddled with little lumps of solder they had to replace it after I left... (I suppose one useful legacy I left was installing about two dozen plug sockets :-))
So far the kids have created some very cool LED pictures each with a fierce amount of soldering and now are ready to hook them up to Arduinos. Hence the need to stay one step ahead of the younger generation ;-)
If you're curious, here's the code for the LED chasing. It's C with some special built-in functions like setup(), delay(), analogRead(), etc.
#define LED_COUNT 11
#define DELAY_MIN 10
#define DELAY_MAX 400
#define DELAY_STEP 50
#define POT_PIN 5
#define INTERNAL_LED_PIN 13
void setup()
{
for (int i = 0; i < LED_COUNT; i++) {
pinMode(i, OUTPUT);
digitalWrite(i, LOW);
}
pinMode(POT_PIN, INPUT);
pinMode(INTERNAL_LED_PIN, OUTPUT);
}
int ScaleDelay(int in)
/* Calculates a delay between DELAY_{MIN,MAX} from an analogRead.
*/
{
float d = (DELAY_MAX - DELAY_MIN) * (float)in;
d = d / 1024 + DELAY_MIN;
return (int)d;
}
void LightLED(int led_pin, int last)
/* Reads a delay, lights an LED on led_pin; turns off the last one a short time later.
*/
{
int d = ScaleDelay(analogRead(POT_PIN));
digitalWrite(led_pin, HIGH);
delay(d / 10);
digitalWrite(last, LOW);
delay(d);
}
#define TAIL_LENGTH 3
int tail[TAIL_LENGTH];
int tail_pos = 0;
int LastLED(int current)
/* Maintains a list of lit LEDs. Returns the very last one.
*/
{
tail[tail_pos] = current;
tail_pos = (tail_pos + 1) % TAIL_LENGTH;
return tail[tail_pos];
}
void loop()
{
int last;
for (int i = 0; i < LED_COUNT; ++i) {
last = LastLED(i);
LightLED(i, last);
}
digitalWrite(INTERNAL_LED_PIN, HIGH);
for (int i = LED_COUNT-1; i >= 0; --i) {
last = LastLED(i);
LightLED(i, last);
}
digitalWrite(INTERNAL_LED_PIN, LOW);
}
November 1, 2006
Backstage: Get with the Program
Posted in: Software, TechThere was a neat idea recently on the BBC backstage list to produce a tag cloud of words in subject lines. There was an implementation of this but as usual with almost everything posted on Backstage no code.
It's frustrating that the BBC go to all the trouble of making their data available and then developers horde their little snippets of code. I just don't understand it. Big kudos to MighTyV who do open source their code. And deservedly won the BBC Backstage competition.
So, without further ado, some code to implement tag clouds off mailing list subject lines:
#!/usr/bin/perl
use warnings;
use strict;
use Email::Folder;
use HTML::TagCloud;
my $mbox = shift || "$ENV{HOME}/Mail/Lists/Backstage";
my $cloud = HTML::TagCloud->new;
my $folder = Email::Folder->new($mbox);
my %word_count;
foreach my $subject (map { $_->header("Subject") } $folder->messages) {
my @words = grep !/^(to|you|we|the|and|would|on)$/,
grep /^\w+$/, split ' ', $subject;
$word_count{$_}++ for @words;
}
$cloud->add($_, 'http://realprogrammers.com/', $word_count{$_}) for keys %word_count;
print $cloud->html_and_css(50);
(I'm happy to comment this for anyone wishing to play with it.)
October 29, 2006
Converting Movable Type URLs
Posted in: Movable Type, Software, TechBack in Aug of 2004, I switched my blog to use descriptive URLs rather than the old-style, Movable Type 2 default of /archive/002981.html.
The downside to this is that after the site rebuild I had effectively created a whole 'nother blog, one all crosslinked in the new style, and one in the old style. And because the rest of my site has random links into the old style from before the change it continues to be crawled. To this day I still get search referrals pointing to the old site.
This isn't so bad except for two things. Comments go to the new site, not the new one. So referrals where someone's looking for rent scam help would, on the old site, miss out on all the useful (and entertaining in some cases) comments. The other bad thing is that the old site isn't running ads. OK, you might think that's a good thing :-)
So tonight I decided to fix this. Here's how I did it.
Overview: Redirect!
The strategy I took was to produce a set of redirects from the old site to the new site. The best way to do a redirect is at the webserver level as it teaches crawlers and browsers where the new pages are. There are in fact two types of redirects, temporary (aka "302") and permanent (aka "301"). Apart from being correct, the latter is also the preferred-by-search-engines method--tales abound of sites losing PageRank for using 302 temporaries.
Using the Apache webserver, I needed to produce a whole pile of RedirectPermanent directives to be included in paulm.com's Apache configuration.
MT code to the rescue
For this I need to get a list of all my blog's entries and create URLs for their new version. I can create the old one easily as the URL is the blog entry's internal ID, zero-padded out to six digits. To create the new URL I had to dig around a little in MT's guts and call MT code directly.Here's the answer,
export PERL5LIB=/home/mt/cgi-bin/lib
perl -MMT -MMT::Blog -le '
$mt = MT->new(Config=>"/home/mt/cgi-bin/mt-config.cgi");
$b = MT::Blog->load(13);
@e = MT::Entry->load({blog_id=>13});
for $e (@e) {
printf "RedirectPermanent /inchoate/archives/%06d.html %s\n", $e->id, $e->archive_url;
}' > /etc/apache2/paulm.com-redirect.conf
OK, what's going on here. First we need to create an instance of the top-level MT object. (Here we see an awesome example of how to abuse Perl's object model--subsequent object instantiations, e.g. MT::Blog make no reference at all to that MT instance, it all just magically works. Ah, pixie dust.)
Next up we load up my blog object. I know its id is 13 by looking in the mt.cgi URL: blog_id=13. Alternatively you can look in the mt_blog database table. I don't actually need this line of code as it turns out I can pull the blog entries out directly. I decided to leave this line in there for some extra documentation and reference.
So the load() method works with several MT types, the ones sublcassed from MT::Object, and has a fairly rich interface. This example shows loading all the entries of blog_id 13. Reassuring when I print scalar(@e) I got 336 which is the same number as reported on my blog dashboard page.
After divining that MT::Entry::archive_url was the right method for printing an entry's URL the ball's in the net. The final piece was manually constructing the old-style URL using printf "%06d" which says "print this decimal zero-padded to six digits".
Now in my /etc/apache2/sites-available/paulm.com I simply added,
Include /etc/apache2/paulm.com-redirect.conf
and kicked the webserver,
apache2ctl config && apache2ctl graceful
(&& is an improvement on ; in that it'll only execute the next command if the first succeeded.)
Finally I of course needed to test it worked, paulm.com/inchoate/archives/002950.html. Yep!
And in the logs,
perl -lane 'print if $F[8] == 301 and $F[6] =~ /\d{6}/' /var/log/apache2/paulm.com-access.log
x.x.x.x - - [29/Oct/2006:23:46:20 +0000] "GET /inchoate/archives/002919.html HTTP/1.1" 301 279 "-" "Mozilla/5.0 (Macintosh; U; PPC Mac OS X Mach-O; en-US; rv:1.8.0.7) Gecko/20060909 Firefox/1.5.0.7"
Do I need all those redirects?
Now, the exceedingly smart and observant reader will note that I haven't used the old-style URL for two years. So two years' worth of blogs aren't written out to the disk in that old format and that means two years' worth of 301 redirects I don't need to have Apache consider. So I'm going to clear them out of thepaulm.com-redirect.conf. One option might be to re-run the script above and put the date as a constraint in the MT::Entry->load() call. This would require me to figure out how to do that and, being lazy, I just can't be bothered (if you know, feel free to leave a comment). So I'm going to throw my sys-admin skills at the job instead.
But... I can feel a two-in-one trickshot coming on. But to set up this trickshot, another observation:
I still have "two" blogs. I need to remove those old pages. It would be easy to just go ahead and wipe them out with rm inchoate/archives/00*.html but I'm curious to see if anything's left after I remove only we know about.
Can you see the trickshot? I'm going to remove the unnecessary redirects and at the same time remove the old files, all in a one-liner. So, I re-used the results of the last bit of code (redirect.conf) pulling out the old-style URLs (/inchoate/archives/002918.html) and turning them into their place on the filesystem. Now I can test to see if they exist and if so, remove them and keep the redirect line, and if not, remove the redirect line.
perl -ani~ -e '-f ($f = "/home/www/paulm/paulm.com$F[1]") and unlink($f), print' /etc/apache2/paulm.com-redirect.conf
This scary bit of code does an in-place modification (-i) of the redirect file saving a copy with the ~ extension in case I make a mistake. I make use of the surprisingly little-used -a switch which splits the line into the @F array ('a' for 'awk' which by default has these in $1, $2, etc). So $F[1] is the old-style URL. If the file exists, the -f test, then unlink (remove) it and print the line. The effect of printing the line retains it from file.
So as an aside we see two perl one-liner idioms,
perl -ni~ e 'print if $some_condition' to remove lines except some and perl -pi~ -e 'do_something_with_each_line(); # typically an s///'
Back to the job: I want to observe what happens, so I take before and after shots with ls $paulm/inchoate/archives/00*.html; wc -l /etc/apache2/paulm.com-redirect.conf. I.e. take the before shot, run the above perl line, and re-run the ls; wc -l "after" shot. For the latter I get, reassuringly,
ls: /home/www/paulm/paulm.com/inchoate/archives/00*.html: No such file or directory
47 /etc/apache2/paulm.com-redirect.conf
Since this has changed my apache configs another webserver kick's needed.
And categories, monthly archives, RSS, and...?
It's all well changing the entries but what about the old-style archives/2004_08.html? Laziness prevailing here again I checked the last week's logs for references,
ls $paulm/inchoate/archives/200*_*.html # this revealed four from 2004, hence: grep archives/2004_0 $logs
Nothing. Delete 'em: rm $paulm/inchoate/archive/200*_*.html
The same wasn't true for categories unfortunately,
grep cat_ $logs
yielded one repeated result appearing. I traced this to a single blog entry which I manually edited and rebuilt. After that I deleted the
cat_*.html pages.
The old RSS feeds could go, rm $paulm/inchoate/archives/[0-9]*.xml $paulm/inchoate/[0-9]*.xml
Correcting old links
We're not done yet! I want to make sure the rest of my site isn't referring to the old pages. No harm would come of it if I left it as is but I'd rather finish the job, and it'll keep my logs clean too.My site's built from little XML fragments and full HTML pages, so I'm going to look in all of them and switch references to the old style,
find $paulm \( -name '*.html' -o -name '*.xml' \) | xargs grep -l 'inchoate/archives/00' | tee /tmp/old-style-pages
This returned a bunch of blog and non-blog (i.e. "home page") entries. The blog entries will require actually fixing the entry in the database, but I can fix the static files easily enough right now. I can also fix the blog files and they'll be fine until I do another rebuild.
There were tantalisingly few there (about four)--I was sorely tempted to hand-edit them. But no, see if I can whip out another one-liner in less time than it takes to look each one up:
</tmp/old-style-pages xargs perl -pi~ -MFile::Slurp=read_file -le '
BEGIN {
%h = map { (split)[1 => 2] } read_file("/etc/apache2/paulm.com-redirect.conf");
s~http://paulm.com~~ for values %h;
$re=join "|", map "(?:http://paulm.com)?$_", keys %h
};
s/($re)/$h{$1}/ge'
The neat trick here is that I'm doing an in-place file change while using the BEGIN clause to slurp in the redirect file and make a hash mapping the old style pages ("word" 1 of the line) to the new URL ("word" 2). Skipping the next line for a second I create a big regex to match any reference the old-style URLs.
Now those mystery references to http://paulm.com: This is quite subtle. The references in the script to my base URL http://paulm.com combine to remove that from the URLs in the pages. By not replacing with the full URL, the script also works on matches on filesystem references, e.g. /home/www/paulm/paulm.com/inchoate/archives/002918.html. Without it you'd end up with /home/www/paulm/paulm.comhttp://paulm.com/inchoate... (I didn't get this the first time round; only after I ran the script on one page and noticed it on a file that did an INCLUDE of a blog entry).
(By the way, if you're thinking, my god, who writes scripts like that off the top of his head? The answer is, if you're prepared to experiment, play, and believe it's possible: "you")
What next?
The test for success here is no 404s (missing pages), just 301s (permanent redirects). So over the next few days I'll be keeping an eye on my server logs using techniques shown above, and tail -f the error log in a window.
Moral
Changing one's URL scheme is not something to be undertaken lightly! However, if you do choose to, having a blogging engine that enables relatively straightforward construction of scripts and one-liners to manipulate its data renders the job a matter of a half-hour or so of reading docs and experimentation.
And of course behold the power of perl and unix to perform sophisticated data transformations and get the job done!
February 3, 2006
I'm so over managing hardware
Posted in: TechYesterday afternoon one of my servers crashed. At 16:20 I got on the case, and it was finally resolved by 20:30. It required putting a new PSU in the server, and sundry post-crash sysadmin jobs. Most of the time spent however was a product of some of the worst customer service I have ever experienced.
It turns out that the company that houses a server of mine was bought out recently. The difference between service from Mailbox before and after has been a stark illustration of the difference between dealing with a company in it for the cash and a company in it for the love of what they do.
Usually when I've called up Mailbox (which is usually only about once a year, mercifully) one of the highly technically adept and friendly guys has plugged in a monitor and checked it out, usually with direct contact on one of their mobiles. While it's no way in their SLA, they just get on with it because they're geeks and know the score. Thus far it's been fabulous.
All that however has changed. Mailbox were recently bought by 186K in Leeds and the Fulham data centre is running on a skeleton 186K staff (their words). In fact, so skeleton there was, I was told by first line support, only one person in there.
Last night I had a fan fail in one of my servers at their Fulham data centre. I called at around 16:25 and, after 12min waiting to get through, heard about the buy-out. I was then informed the best they could do was do a server restart. I would really rather avoid just powercycling a box when there's the possibility of a fix after a typically tiny amount of command line diagnosis (in the past restarting apache has been enough, for example).
This one person in the data centre was adamantly jobsworth about it, point blank refusing to make any effort to plug a keyboard & monitor into a server. (There were an account manager after all! The fact that my 60+ yr old non-technical mother will happily plug in a keyboard & monitor to a computer is notwithstanding...)
This process of discovery of the technical non-capabilities of the single person in the data centre took no less than 15mins of being put on hold for ages while the 1st line support guy called the datacentre back, over & over. Essentially what could've taken 4mins with a direct line to the guy in the data centre resulted in 15+mins of wasteful relaying. Eventually I succombed and said "ok, do a restart" at which point the chap had decided to leave, before five o'clock. So effectively midway through dealing with a customer's server crash, off they went.
Mind boggling, and phone bill grinding up I escalated up to one of their sales team members. At this point actually useful stuff started happening. They mysteriously found another person at the data centre (I still don't quite understand this) who did the restart. This didn't help so I said, I can head down there ASAP. The same thing essentially happened: there was so much on-hold action that the remaining staff had left again and so I couldn't visit the centre after all. We're up to 17:30 having started 70mins ago.
There was a happy ending - one of the previous Mailbox employees got involved! He Tubed in from east London, opened the place up, and we gutted random spare machines for PSUs (fan had failed), fscked the disks, and I scootered at high speed to PC World for a replacement PSU. So 186K acquitted themselves, beyond the call of duty actually, in the end, although I hope they review what happened to get to the point where they were sending ex-employees across town to get a result...
January 1, 2006
discontinuity of civil time
Posted in: TechA discontinuity of civil time occurred this morning at midnight on New Year's Eve... But that's not the reason for the number of police out in London last night. As the clocks struck 12 (or 00) there was a leap second inserted to correct for the time getting fractionally out of step with the Earth's rotation, thus causing a momentary discontinuity. The last time this happened was seven years ago.
How this happens: the same second happens twice, represented differently,
2005-12-31 23.59.60 <-- leap second 2006-01-01 00.00.00
Those are both the same times (00.60 is 01.00 so 59+01 = 00.00 and so on). More technical background on the Network Time Protocol leap second page.
Unfortunately for some computers that implement the time shift by going back in time by a second (as opposed to say holding the time for that second or "slewing" [sliding]) this can cause problems. Whose idea was it to risk computer bugs on the most hungover day of the year?
PS Have a great 2006!
December 21, 2005
Pocket PC Tabata Timer
Posted in: Phone, Software, Sport, TechBack in April, on my birthday even, I put out a little .NET application that helped in timing intervals for training. In particular it defaults to the tricky-to-time Tabata whose brutal schedule consists of eight 20s-on, 10s-off periods (i.e. 3:50 mins total). At the time it didn't work without the as-yet-unreleased .NET 2005 Beta and it wouldn't work on 2003 and I couldn't get my device to work and ... anyway. It's all working again now,
IntervalTimer-20051221.exe (11K)
Copy this onto your device e.g. in \Program Files (I don't know how to do Pocket PC installers yet) and then run it from File Explorer. This ought to execute on a desktop machine too; it does on my XP box here.
N.B. This version includes a 10s countdown after hitting Start. Then the pain starts. The lurid colours are deliberately full-screen like that so you can see the changes when your device is a way away from whatever punishment you're dishing out to yourself.
Enjoy!
December 2, 2005
SQL Friday fun
Posted in: TechAfter Tuesday's Google interview wherein I was asked all sorts of tricky little questions, here's one of my own.
I'm currently reviewing a dataset to see whether I can implement a UNIQUE index on one of the columns. This is pretty straightforward. I want to join a table to itself where the values are the same but the primary key is different:
select ct1.uid, ct2. uid, ct1.value from code_tree ct1 join code_tree ct2 on ct1.value = ct2.value and ct1.uid != ct2.uid;
+------+------+-----------+
| uid | uid | value |
+------+------+-----------+
| 190 | 184 | bars |
| 184 | 190 | bars |
| 1333 | 1283 | Up |
| 1334 | 1284 | Down |
| 1335 | 1293 | Unchanged |
| 1283 | 1333 | Up |
| 1284 | 1334 | Down |
| 1293 | 1335 | Unchanged |
+------+------+-----------+
Can you see the problem? What's the least change required to Do The Right Thing?
Answer below:
Simply change the != to a > sign:
select ct1.uid, ct2. uid, ct1.value from code_tree ct1 join code_tree ct2 on ct1.value = ct2.value and ct1.uid > ct2.uid; +------+------+-----------+ | uid | uid | value | +------+------+-----------+ | 190 | 184 | bars | | 1333 | 1283 | Up | | 1334 | 1284 | Down | | 1335 | 1293 | Unchanged | +------+------+-----------+
(I picked > rather than < so I didn't have to escape the HTML entities in this blog post ;-)
PS Sorry about the line spacing above; I think it's a Movable Type bug.
November 14, 2005
Software "on" ipod
Posted in: TechJust as Sony is embarrassed by and switches off their "copy protection" I am enjoying technological interoperability thanks to my music player, USB, Apple, Linux, and Things Just Working™.
I just checked out a branch of some BBC code I'm working on onto my ipod Shuffle. I can hack directly on it at home on my Powerbook, stick it back into the Linux development box, and then just run a commit. In the time it took to sync the repository the device got a little charge off the USB port. Now I'm listening to it. Wild stuff!
(To have your Linux box talk to your Shuffle all that's probably needed is,
mkdir /mnt/ipod
cat >> /etc/fstab
/dev/sda1 /mnt/ipod vfat sync,user,noauto,umask=000 0 0
^D
mount /mnt/ipod
More details here)
October 12, 2005
Nordic Perl Workshop
Posted in: TechIn a series of moments of randomness, and a desire to not completely neglect my corporate education (e.g. attend at least one Perl event every two years) I'm off to Stockholm, my first time in Sweden, to the Nordic Perl Workshop, a two-day grass-roots conference covering a wide range of the technologies I'm using or am learning to use. Fab!
By a random coincidence it so happens this is on... Heh.
October 11, 2005
Lift game theory
Posted in: TechThe natural reaction to seeing a lift (a.k.a. elevator) with its doors open and full of people is to make a bolt for it, squeeze in before the doors close. This to avoid the tedious wait for another lift to chug down and grind its weary cogs open.
Having recently been using some very slick lifts in a busy building it's occurred to me that this behaviour is subject to a subtle assumption about lift dynamics.
What's interesting here is that if some of these variables are changed, this behaviour of running for a soon-to-depart lift actually works against users in the sense of potentially making their journey longer. What's even more interesting is that this situation arises when there is more than one lift and those lifts run faster than your average vertical conveyor. That is, with an apparently better provision of lift service you're better off not running for it.
So how does this peculiar situation occur? Consider two lifts both in the lobby of a hotel. Someone hits the Up button and so one of lift's doors duly opens. A couple of people step in and press for floors 3 and 6. A third person a little way off spies the doors open and makes the customary dash for it, just getting in as the doors close. The new entrant selects floor 2.
You may have spotted where this is going. For the first two people, their journey is now slower having taken a passenger who's stopping before their floors. Conversely, had the third person selected floor 7 her journey would've been slower by having to stop at a couple of floors first.
What's the alternative lift catching strategy? When there is more than one lift waiting at a given floor, a faster strategy for all users is to spread themselves out over the available conveyances. This means simply allowing the first lift to close and get under way before hitting the call button. (In every lift I've ever tried this on pressing the call button is either ignored if the doors of a lift are already open, or, arguably a mis-feature in the lift's programming given this discussion, the doors of a closing lift re-open.)
So with more lifts ready and waiting a better strategy is to let the existing lift set off, and catch another. I asserted earlier that the jump-in-quick behaviour could be wrong if the lifts are fast too - how so? Even if a lift isn't ready and waiting, it may very well be soon in the case of a speedy adjacent lift (this idea does require at least one other working lift: of course it'll be quicker to join a single lift than wait for it to return). For example, a second lift on the third floor being called to the lobby. The wait time for the call may very well be less than the cumulative waiting for the other occupants' stop-off on the ascent. This effect is probably more pronounced for those working on higher floors who have probabilistically more to lose getting into a crowded lift.
September 8, 2005
Perl Brainbench test
Posted in: Tech[Re-instating this entry after a database glitch!]
Brainbench is a company that provides online tests primarily aimed at employee assessment. Since I write software primarily in perl I've been curious about what I'd manage on it for a while now. The Perl Brainbench test has been around for years and has a good reputation in the perl community in terms of fairness, accuracy, wording, and scope of questions. Many, many perl programmers have taken it.
I finally took it today and scored 100% putting me in the top 5% of other test takers which I'm pleased with. One thing I didn't realise was that how fast the questions are answered has some bearing on the final grade; ah well. Anyway I'm particularly pleased with the score since I didn't cheat e.g. by taking a practice run at it. It's certified against my jobs(at)paulm.com address.
September 2, 2005
A very large mailbox
Posted in: TechIn some cobwebbed recess of cyberspace there is a machine running, and I happen to have god privileges on it. Dusting off a route into the box, I logged in and found what seemed to be rather a lot of system mail; about 90MB or so. Opening it, and watching the progress counter glacially increment, I quickly realised it was much much bigger than 90MB. I'd missed a digit, it was nearly a gigabyte. That's nearly half of what gmail offers, all in a single folder. It's not often you find that kind of thing lying around...
Rather than just kill the mail program I left it, out of curiosity to see what would happen. It consumed essentially almost all the resources this poor, although hardly badly specified, machine had. Having scanned the whole mailbox it then tried to sort it, presumably by date. And tried, and tried.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 18657 root 18 0 862m 394m 100 R 0.7 78.4 3:37.04 mutt
All 512MB of RAM and nearly all the 500MB of swap were used and it was essentially stuck attempting to sort over a million messages. I've been generous; I'd been to the gym and back and it was still busy.
Looking at it by hand: it'd been checking a website and failing, every minute, for a little under two years. Moral: set up mail aliases to attended mailboxes ...and at least occasionally log in and say hi :)
July 2, 2005
MySQL Perl DBI last_insert_id
Posted in: TechFor some reason I couldn't get a quick answer on how to use last_insert_id(), just reams of P°H°P pages or out-of-date and/or driver-specific stuff e.g. $dbh->{'mysql_insert_id'}, so here's the answer:
$dbh->do('INSERT INTO a_table ...');
my $id = $dbh->last_insert_id(undef, undef, qw(a_table a_table_id))
or die "no insert id?";The two undefs are for catalog and schema which don't appear to be necessary. The DBI docs say they can be ignored for MySQL so you might not even need the table and field parameters. Doesn't hurt to programmatically document though.
Enjoy!
PS I'm only using MySQL as it's a legacy system. Of course, real men use sequences and PostgreSQL!
June 29, 2005
spamcop blacklist considered useless
Posted in: TechIn the world of spam countermeasures there are Realtime Block Lists, lists of IP addresses (= mail servers on the 'net) that are considered to be in violation of some policy, e.g. too much spam, breaking some internet standard or whatever. These lists don't require you use them, and they don't even otherwise interact with mail delivery: they're purely a third-party opinion. Based on their effectiveness you consult them or don't.
I've just discovered a whole pile of what I consider legit mail having been filed in my "Warning" folder (which is usually almost entirely spam) because spamcop.net's blocklist has Google's Gmail service blocked. It's kind of pathetic reading the spam zealots defending this based on numerical analysis. Yes, Gmail servers have been used to send huge gobs of spam but considering the job of delivering mail practically who really wants a list that blocks a massive mail provider's feed? They've also blocked yahoogroups. I mean, really, come on guys, reality check!
May 22, 2005
How to get internet from a hospital bed
Posted in: Injury Time, Tech Since being in hospital Saturday 14th I've had no internet connection - there is no wireless here, nor any Ethernet, nor even a crappy bedside unit. There is a bedside unit that does TV and radio, and is supposed to do 'net but it doesn't work, and besides has an awful PDA-style keypad.
Since being in hospital Saturday 14th I've had no internet connection - there is no wireless here, nor any Ethernet, nor even a crappy bedside unit. There is a bedside unit that does TV and radio, and is supposed to do 'net but it doesn't work, and besides has an awful PDA-style keypad.
For the first few days Nik ever so kindly shuttled his powerbook back and forth with my mail downloaded for offline tinkering. This worked pretty well all-in-all but obviously I couldn't use the Web or do any work. We did try to set up a dev environment but it was quite hard work and out of both our areas of knowledge.
Word got out I was banged up in hospital and Saul Albert of wirelesslondon.info rocked up with two laptops, a 12V car jumpstart battery, a directional wifi antenna, and reams of various cables.

A miracle the nurses tolerate this kind of "ops centre" annexation...
By this stage I'd taken up residence closer to the window for precisely the purpose of getting a wireless signal at some point. And today was the day...
Saul set up his laptop and connected it to the antenna mounted on a tripod (with rubber bands and medical tape!). Using NetStumbler to scope out the radio space:

I can smell a Wireless!
We found a variety of nodes, some open, some encrypted. All unfortunately showed pretty weak signals ... apart from one! Down in Waterloo train station there appeared to be a commercial hotspot with a reasonable signal.
Firing up a webpage showed the usual "pay here" splash page. As it turns out only a handful of the usual internet "ports" were metered: web, mail, and SSH. Saul has SSH running on a non-standard port on his server so connected straight in. From there, I could get to my box and run my own non-standard SSH server (sshd -p 12435).
Now for the web: I needed to find a proxy to bounce all my requests through. The neat solution to this is that there's no need for additional software, simply point the browser's connection settings at another machine and all web requests go through there, very commonly on a non-Web port such as 3128 or 8080. Non-web port in this case means the hotspot isn't metering it! I.e. it's no cost to me.
Fortunately, there are collections of open proxies kept up-to-date minute-by-minute, proxies that are typically misconfigured to allow anyone to use them. These are normally a curse since they're abused by web spammers, but in my situation, a blessing. Using a text-mode browser on the SSH connection we found a few, tested their response with ping, and tried a couple. There was a very fast one in the UK that appeared to be a corporate proxy but turned out to be running quite a severe content filter (good enough to haul 30+MB of Windows Update though :-)). A couple of other usable ones in Germany and Italy we found without too much hassle and bingo, we were on the Web!
The Mozilla/Firefox Switch Proxy Tool was a great help in testing and switching between various sites.
As for mail, by the power of SSH's local port forwarding capability I now also have IMAP and SMTP tunneled direct to my server through the non-standard port. (ssh -C -N -f -p 12435 -L143:127.0.0.1:143 -L25:127.0.0.1:25. -C = compression; -N = no shell; -f = background. I've given the SSH command line but I actually did it with PuTTY.)
Since then I've at last figured out how to have Apache act as a proxy, which I'll write up since I couldn't find any copy-n-paste examples. In the meantime, here's a listing for a sample httpd-proxy.conf I wrote.
The final tweak was downloading and installing vendor drivers for the wireless card I'm using - under Windows 2000 the default wireless drivers aren't great and the connection would pop in and out every few seconds. Now it's solid.
I've moved over to my cute little tripod which is currently perched next to my bed:

Bedside aerial
The next upgrade, if I'm in here long enough to warrant it, is to get the antenna by the window attached to a router rather than wired next to me which is a bit of a pain. It's not that much of a problem since I don't actually move anywhere...
Thank you Saul! (And thank you unsecured hotspot owners!)
Shameless plug of Saul's project: Imagine anyone could share wireless internet all over London: that's the vision of wirelesslondon - check it out, anyone can help.
April 21, 2005
Learning with humor
Posted in: TechIn my quest to learn about redundant firewalls I've had to understand how Internet routing works. Another on my "vaguely understood for at least half a decade" list that's coming into much sharper focus. In the course of learning about HSRP, Hot Standby Router Protocol I discovered RouterGod, a series of articles on low-level internet arcana presented as... celebrity interviews! E.g. Paul Hogan tells us about HSRP! They are absolutely fantastic, especially 7 of 9 on OSPF
Once your OSPF routers have communicated with their neighbors, they begin to organize themselves into a military like hierarchy with routers occupying roles as Generals, Captains and Lieutenants. During this phase they are still weak. This is called "forming adjacencies". It is during this phase that you should rip your OSPF routers from their racks and beat them to death while you still have a chance.In the next phase the OSPF routers will suddenly and without warning broadcast their message of doom to all other OSPF enabled routers. The OSPF Task Force calls this "Flooding Link State Advertisements". Once this occurs, every router knows what the entire battlefield looks like. Some people call this map of the battlefield a "link state database", but calling it an innocuous name does not make it any less threatening. Now they have knowledge, soon they will each run their Shortest Path First algorithm and they will posses intelligence. [...contd]
Crazy thing is, I've read half a dozen of them and remember almost all of it! Including never charge less than $1000 to set up HSRP and always get the money up front, before your customer sees that you fully configured HSRP on 2 routers in less than 5 min! #.
April 20, 2005
Firewall hijinx
Posted in: TechI've been neck-deep in iptables trying to set up a dual redundant firewall out of a pair of Linux 2.6 boxes. I'm currently moving from a six year long fuzzy phase of vaguely understanding how iptables works to rapidly upgrading that into a solid working knowledge: enough to actually create something non-trivial, on my own. Put another way, enter an endless loop of typing commands, reading documents, (note the order there), puzzling at why it doesn't work...
So in the course of all this something quite technically funny just happened...
Still at the stage of quite early set-up. To get the basic address translation and routing sorted, I'm testing with one of the fw boxes pretending to be a server in the DMZ. Thus external requests are translated and forwarded from the fw to the server, and server requests are similarly translated back out.
So in order to test this I set up a forward (DNAT) from fw:80 to server:80 and tried to hit it from outside. Not working. After a fair amount of time in the aforementioned methodology of semi-mindful experimentation... success! I must've tried about every possible thing including a variety of IP changes, switches, deletions including to find out which of the nine interfaces I was dealing with was disconnected (two of them apparently).
Now, in order to reduce complexity I had at some stage dropped the ports aspect of the incoming translation - i.e. make the rule wider to translate everything from fw to server. In other words, the fw disappears to new connections! Now, I had my existing ssh connection kept alive; had I lost that I'd've been SOL with no access to the fw. I hadn't realised all this yet....
Back to the story: Having figured out exactly which of the various things I did had impacted exactly which aspects of the various connections I was working on I started to put the rules into the FWBuilder config I'd built. All sorted, I uploaded it to the fw. Except the SSH connection used to upload the firewall config was forwarded to the server! D'oh! Server promptly vanishes to the network having been firewalled off with wrong IPs.
Shit. I'll have to call the NOC and get a powercycle (and run risk of fsck barfing) or wait 'til I'm next down there. Shit.
But no! By some ridiculously improbable fluke a another machine in the cabinet had the fw's IP stored in its arp cache with the server's MAC address - bing, bypass forwarding and we're in!
Firewall:
porus:~# ifconfig | grep -A 1 eth0
eth0 Link encap:Ethernet HWaddr 00:E0:81:60:C3:EB
inet addr:217.207.14.103 Bcast:217.207.14.255 Mask:255.255.255.0
Random local cabinet host:
stix:/tmp# arp 217.207.14.103
Address HWtype HWaddress Flags Mask Iface
217.207.14.103 ether 00:E0:81:60:E1:E7 C eth2
Same IP, different MAC
Lesson learnt: I would've caught this forward from fw to the server by having a different password or key on each. Bad me, the two machines are virtually identical, down to having same root passwords.
Universal lesson repeated for the millionth time: give up after hours at it and get some sleep ;-)
April 11, 2005
No .NET mobile development for hobbyists
Posted in: TechMicrosoft provide their Visual Studio IDE at a variety of price-points, ranging from the cheapest being their "Express" version to "Team Studio", the all-new designator for "Enterprise". The latest soon-to-be-released Visual Studio 2005 has a feature comparison chart for prospective customers. One notable, and IMO disappointing, missing feature is mobile device development from their Express version.
Why might this be a mistake?
The Open Source aka Free software movement has been wildly successful in part due to the zero financial cost of entry and pervasive free development tools. You can get the compiler, editor, everything for no cost. What this means is that a 14yr old can learn PHP and start writing dynamic webpages. (The die-hard software purists might not consider this a feature ;-)). The enormous volume of software at the open source clearing house freshmeat is testimony to the ease with which free software can be developed.
Currently there is a roiling battle over which operating system is installed on your mobile phone. Reading the offers of free accommodation, parties, saunas and all manner of temptations coming out of the development houses it's hard not to recall the crazy buzz of the Web last century. The significant players right now are Symbian, Nokia, and .NET. .NET isn't yet on that many phones but given that the Microsoft gorilla is behind .NET they need to be taken seriously.
So why not put free or extremely low-cost development kits in the hands of even the most vaguely interested coder or potential coder and provide them the opportunity to experiment, build, deploy phone applications, and ultimately become seasoned developers driving adoption of a particular platform. Once they're hooked the likelihood of then developing say a Symbian app which would require substantial relearning would drop dramatically.
Microsoft even follows this logic by offering their MSDN development license to small software vendors for very low cost presumably as a hook into One Microsoft Way. The logical conclusion at least for now when the battleground is still so changeable is to offer free dev kits for phone experimenters?
It is possible to get a free SDK for phones but it's not the IDE, and IDEs for languages like C# make a big difference.
April 10, 2005
My second .NET application
Posted in: Sport, TechI took the mini interval Tabata timer I wrote last night and added programmable work/rest periods, total number of intervals, separate total and interval timers, and, crucially, a fixed 10s countdown to get in position. I think this is pretty well as much functionality as a high-end stopwatch.
Download IntervalTimer_20050410.exe. Still 20KB :-)

Hmm, I'd only really intended this as a way of learning a bit of .NET but it's proved itself quite handy already. Now, if I would only get the b*astard to deploy onto my phone...!
April 9, 2005
My first .NET application
Posted in: Sport, TechEver since acquiring a .NET PocketPC phone I've had delusions of writing software for it, even to the point of obtaining an MSDN development license through their cheap deal for ISVs. Months however passed with other distractions, and generally being daunted (GUI dev from years of writing unix system software is a big jump).
Lacking a stopwatch or decent clock, I wrote an application for timing training intervals.

"Yatta" means "Go!" in Japanese. Dr Tabata is Japanese.
Specifically, workouts based on the Tabata Protocol, a thoroughly brutal 4min experience consisting of 8 intervals of 20s on, 10s off. There's a great description including graphic accounts of workouts over at T-Nation.
The app simply waits for its banner to be clicked then starts timing:

Work it! Interval count is on the right

Rest...

Phew!
Progress bar counts up on the work, back down for the rest. That's it!
Download (20KB)
Yeah, that's 20 kilobytes. You might need a modern .NET core download; try it and see.
January 18, 2005
Wireless London
Posted in: Art, Events, TechTonight I attended a packed lecture hall for the inaugural, and as it turned out engaging and super-smoothly executed, Wireless London event that featured talks from Armin Medosch and Usman Haque. Both were great; interesting and provocative...
In particular Usman's Sky Ear project was just fantastic - send up little radio frequency sensors with powerful LEDs, some communication circuitry, and phones all inside hundreds of helium balloons. The sensors detect both natural- and human-created signals and visualize them with the LEDs. An extra twist is created by the ability to be able to SMS/text the device which in the process of receiving the message affects the surrounding ether and thus the visualization! The scale of the creation was just awesome and looked wonderful.
Definitely recommended, looking forward to the next one.
Continuing what seems to be a run of good fortune meeting cool people, I was lucky enough to be sitting next to an architect who did an intriguing project on the 'flirtatious city' examing how configurations of architecture are and are not conducive to urban intimacy in its broad sense. Gotta love intending to go to Rome and experiment wearing high-heels on a Vespa to see how that effects passage through the urban landscape... Someone has to investigate this stuff.
January 11, 2005
Binary reflex
Posted in: Drivel, Humor, TechYou know you've been hanging around computers too much when...
Dave Gould says: 6 OR 7? paulm says: 7 Dave Gould says: scuse caps lock paulm says: oh, in that case I don't know
November 2, 2004
Crackpots, I tell you!
Posted in: Humor, TechThree entertaining quick reads,
The Ultimate Firewall Intrustion Prevention System. How to create a 100% secure firewall!
From the How-To-Tell-If Departments, rate your contribution to physics! And rate your Final Ultimate Solution to the Spam Problem (quite technical)
October 29, 2004
Stylus shorthand
Posted in: TechThe topic of using phones to foster communities is one of the current bees buzzing in my bonnet at the moment and key is being able to communicate. Talking is one aspect of that, the other is SMS, and (soon) messaging on other protocols. Unfortunately data entry on a phone or even PDA sucks. You're stuck with,
- traditional numeric keypad, 855,5557777#7777882226677771111 !
- T9 predictive text, 8557#78267#6377
- if you have a stylus phone you might have any of block, keyboard, recogniser, grafitti methods. Of those I haven't used grafitti but I imagine it sucks too. Certainly "keyboard" entry sucks.
So here's an idea to reduce the deafening sucking sound around phone data entry...
Shorthand
In a nutshell the idea is to use shorthand as data entry on systems that support a stylus. The kind of shorthand that secretaries, journalists, and so on use. Why? Because shorthand provides access to seriously fast data entry.Background
There exist a few forms of shorthand, the two I'm familiar with having attempted to learn shorthand years ago (and inventing my own crappy one) are Pitman 2000 and Teeline. The former is notable for requiring different stroke pressure (hard/soft) which immediately unappealed itself to me, furthermore it has 'decoration' around the outlines whereas Teeline appears to me far more flowing and economical. And having "2000" in a name is so 80s.If you'd like to see some Teeline outlines check out these from an online course of practice audio files by UK's Goldsmiths University.
There's this too which looks good but I haven't read that either yet.
Rationale
Fast teeliners hit speeds of 150wpm. That's about two thirds the average speed people read, and about twice as fast as I can type, and I'm a full 10-finger no-lookin'-ma touchtypist. So, seriously fast. From what I can gather, 70wpm writing speed is not at all uncommon with a couple of months practice based on standard recommendation of 30mins/day.Shorthand as stylus input
Current recognition software makes some use of the fact that letters are essentially discrete items, with some additional forms to handle joined up writing. This apparently simple task has until fairly recently not really been satisfactorily solved. (The recognition on my PDA is impressively good despite my scrawling).Challenges
Like longhand, shorthand also has discrete letters but they're far more compact so there's less for the recogniser to "grip on to" to distinguish them. Further complications abound: most occurrences of vowels, and all doubled letters are missed out (they're surprisingly unnecessary given context). When vowels are written they're so compact at first sight it's not immediately apparent they're even there. Yet more: there are all sorts of rules to reduce the amount of time the pen is screeing across the page, e.g. letter 'l' written crossing the line is 'pl', drawing one letter through another can indicate a letter 'r', and on.Even once the recogniser has correctly identified the sequence of letters in the outline there remains the issue of ambiguity since the vowels and doubled letters are missed out. Whl ths isnt a bg dl for hmns, cmptrs rnt so smrt. On the plus side there's some compression as a pleasant byproduct so your 160characters goes a little further. Now, if your reader can read shorthand, and the phone renders the SMS back into shorthand, they'll be able to read and recognise the forms/outlines rather than parse them down into individual letters so this won't be a problem. And to be honest most people are used to SMS-speak (even though I know some purists, usually over 25s, loathe it!)
One obvious downside to shorthand as a stylus input method is that most people don't know shorthand. That said, most people didn't know T9 either but have managed to learn it. (Admittedly, T9 is blatantly far easier to learn than shorthand.) Some might compare learning shorthand versus longhand to learning the Dvorak keyboard versus Qwerty but I don't think the analogy holds: Dvorak is really replacing, overlaying, and interfering with an existing skill whereas shorthand is a parallel, additional skill. I've tried to learn Dvorak and once you've mastered touchtyping Dvorak is hard.
Other efforts
This ACM publication, "Shorthand writing on a stylus keyboard" (2003) seems to be researching in a similar space but using a proprietary shorthand. I have the PDF from a friend with an ACM sub but I haven't read it yet.This article on AI Tablet OCR is well worth a read for techs - some successful experiments in DIY AI recognising forms using homebrew neural nets. Wish I had time to play around with this some more.
Conclusion
Despite the obvious speed win, the question ultimately boils down to, is it interesting enough to people to be able to write at 50-70wpm on their phones? Right now, probably not. As applications come online where real-time communications like BBSs, chats, blogging, etc all transition online I think the pressure to break through the currently abysmal state-of-the-art will build.Personal historical drivel
I started learning Teeline many years ago, the idea was that it would make taking notes in university lectures more efficient. Now, being a maths student shorthand is probably the least useful thing I could've been learning so this tells you a) how much I dislike writing b) how much I like to optimise out about every possible boring aspect of my life c) how much I would go to avoid maths :-)
My enthusiasm waned somewhat despite some initial success; it was looking like actual sustained effort would be required to learn this, and making an effort just isn't the done thing for students.
Anyway, I'm going to give it another crack with my shiny ability to learn stuff really damn quickly thanks to NLP and better general self-awareness. I was quite pleased to see after about an hour's study on the tube I'd got through the first four audio files on the Goldsmiths course more or less without error. Let's see if I can stick to it this time ;-)
October 14, 2004
Setting default mailman URL
Posted in: TechThis for mailman list admins only.
Mailman has this concept of a URL that's associated with a domain. Unfortunately it's not possible to configure it through the interface, which on vhosted lists is really annoying. To set, in fact fix this URL, there is an impossible-to-remember incantation with an auxilliary script, fix_url.py. Tired of looking this up and messing up the invocation here's a wrapper.
Actual script on my use.perl journal
I wonder what this script would look like in python (language mailman is written in) and whether it could be absorbed into mailman core?
September 29, 2004
My First Pocket PC Application
Posted in: Phone, TechWoohoo! A real-life little program running on my phone with a label that toggles "Hello..." and "World!" on the press of a button.
Click the image to see what the emulator looks like:

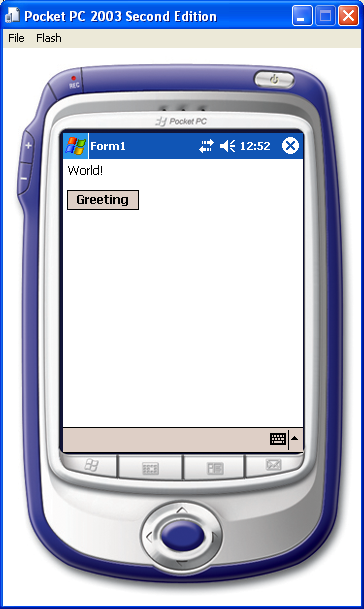{kind=link}
Yes, I've even had that app running on my very own phone!
I must say, I'm super impressed with the development software, Visual Studio 2005 Beta. That app took me all of about 20minutes to produce, after a short time installing it. Admittedly, I have a little familiarity with C# and have played very briefly with Visual Studio Express (the free one) but even so.
Compared to the unbelievably fiddly process of beating the Symbian emulator into operation it was essentially an effortless point-n-click affair. Hit F6, choose to deploy on the emulator and up it pops, including an automatic installation of the latest .NET Compact Framework. Wild. Looking forward to more of this...
Developing phone apps
Posted in: Phone, TechEver since working on the Urban Tapestries project I've been becoming increasingly excited about the possibility of phone applications. These possibilities and their scope from having a highly networked portable tiny computer always about one's person continue to amaze and intrigue me. This evening alone a friend and I came up with an outstanding gadget for tourists; it feels like the Web in the mid 90s.
Enough breathlessness, what's out there?
The downside is that programming for phones is a real drag. The dominant development platform is Series 60, a system based on Symbian developed by the UK's Psion who've made organisers since the 80s. It's now powering untold millions of smartphones by Nokia, Sony Ericsson, and many others. Writing code for series 60 however is not a pleasant experience, the biggest complaint being the dire state of documentation.
After witnessing the length of time taken for a competent developer to create the C++ UT app on the P800, and poking around with it a very little myself, I had a strong suspicion I wanted none of that. It simply looked like too much effort. This is 2004 after all, software ought to be writing itself by now for heaven's sake!
The obvious alternative to C++ is Java, everyone's favorite "cross-platform" language. As usual the reality bares a disappointing and grubby resemblence to the marketing hype: Java solutions don't even provide access to the camera, SMS, and other tantalising phone-specific goodies. The latest Java platform, MIDP2, goes a long way toward solving those deficiencies but I often come away from Java with the feeling whatever happens is far too late, too over-engineered, and not native to anything in particular (read: weird user interface).
Which leaves .NET for phones.
Sure, I could hang on and watch the MIDP2 scene develop. Or I could get stuck in with a working native system by a company who (despite best efforts of many) just won't go away: Microsoft. After sitting in front of the fire in Monterey a few years ago learning C# and .NET basics from a book I came away really impressed. The language and framework just felt right, especially against the bloated design-by-committee proprietary torpidity of Java. But that's a discussion for (probably) other authors and other blogs, suffice to say I knew I wanted to play with it, one day.
Then when I ended up with a Orange M1000 Pocket PC running Windows Mobile 2003 the desire became a realistic possibility...
There is a free compiler MS offer but it doesn't work for phones. An Microsoft Developer Network (MSDN) subscription which would provide the necessary tools is expensive (£1,470).
After some investigation it turns out MS offer a UK ISV "Empower Initiative", a program that provides small companies with a cheap (£260) MSDN subscription presumably in the hopes that they'll be suckling on the Microsoft teat for evermore. (And I don't say that jokingly: this last week I met a guy who said more or less word for word, "yes, we're a Microsoft shop, back when we started they provided us some training material.")
After some discussion about tentatively exploring porting the UT app to Pocket PC Giles at Proboscis signed up for the UK ISV program (ironically on a Mac emulating a PC as their entire org is Microsoft-free!). The DVDs arrived, Visual Studio 2005 Beta's installed and off I go...
September 27, 2004
Dorkbot London classic!
Posted in: Events, TechLast Wednesday's Dorkbot, its return after way, way too long was a real treat. The evening went from self-modifying music software being edited by its author and itself in real-time, to an oil-painting of a stereogram (a celebration of functionlessness aka "being shit"), progressing from a clock made from a Mark's & Spencer's prawn sandwich(!), into the possibility of using other people's wireless networks to communicate without their knowing, and finally quite possibly the coolest ever wiki.
{kind=link}
Saul Albert (one of the Dorkbot London co-dork-founders-organisers) wrote up a nice review of it that I've posted below with his kind permission.
(To hear about these events in advance check out my events mailing list and the archives and upcoming.)
Saul sez (my comments interpersed):
Well, Alex Mclean started by doing something he said he'd never do : talkthrough a website (!) but it *was* a very interesting on: toplap.org - the Temporary Organisation for the Propagation of Live Algorythmic Programming. He introduced us to the idea of 'grades' - equivalent to grades you get when learning the piano but insisting instead that in order to attain Toplap grade 2 you have to be able to make nice music with the system bleep. Then he gave a very engaging example of how LAP works - writing several little sound making scripts from scratch and explaining as he went along how he was doing it. My favorite bit was when PaulM demonstrated the new and wonderfully expanded possibilities for heckling (heckling?! helping! - Paul) this kind of performance by shouting,'You've missed a parenthesis on the end!'
And (more in keeping with tradition) throwing a half full bottle of white lightning cider at the stage. (er, this is a joke - Paul)
Alex mentioned that he'd written an article about this that has links to source code: http://www.perl.com/lpt/a/2004/08/31/livecode.html
Rory Macbeth talked wonderfully about his evil nauseating magic eye paintings - and how they're a bit like abstract art with a little hidden trick or reward for people who know 'what it means' but really because it's done in a kind of 60's splash painting style the magic eye bit doens't work so it's actually a kind of nauseating representational painting of a magic eye painting, but then he plugged the bloody thing in and it started vibrating - emulating how magic eye paintings do that shimmering thing when you try focus on them, which made the whole thing really quite impossibly stupid. I wanted to buy this painting from rory but he won't take any money and said if I wanted it I was probably stupid enough to deserve it.
Then what can I say, James Larsson demonstrated his prawn sandwich based clock, an expanded version of the too-compressed presentation he made at notcon (but I will link to that cos there's a video: http://www.ejhp.net/notcon/NotCon-Hardware-high.mov. Interestingly, the clock was extremely accurate (well, within an hour and a half) which is very impressive considering that we only gave James three days notice - which in these terrible days of over-processed preservative-filled-food, wasn't really enough to rot a Marks and Spencer's prawn sandwich to the point of complete deadliness when it becomes unstable enough to produce interesting changes in the conductivity and electrical resistance of the bread, mayo and prawns.
Paul: This presentation really was as engaging and funny as any I've seen at dorkbot. James simply IS a mad scientist and was kind enough to give me the technical low-down. The system worked by measuring the decrease over time in the conductivity of the bread versus the change in capacitance of the prawn as it decayed. The mayo's resistance (IIRC?) was tracked too. A BBC Micro with its built-in 4-channel 12bit ADC provided the logging. The resulting three-variable plot was collated into an enormous array which provided a list of "events" both in absolute value changes and variables relative to one another, as I understood it. So the clock was event driven and would move about 40-60mins each event. (I also had a fascinating pub-chat and lift home with James during which time we talked a bunch of other esoteric stuff -- fantastic!)
Then Jeremy Ruston presented the wonderful TiddlyWiki and gave a very useful breakdown of how wikis work, and how tiny bits of microcontent (tiddlers) can help to merge the facility of blogs to organise and produce microcontent with the non-linear and collaborative way that wikis structure things. Rory Macbeth who continually apologised for not knowing about or being able to do anything with computers (which is not true - I know Rory and he has magic computer fingers that can destroy hardware, corrupt files and crash otherwise stable software for no reason within seconds of him sitting down to check his email) said that he understood TiddlyWiki and would consider using it.
Then Matt Westervelt got up and presented this very cheeky hack: Other People's Networks - a (fictional, but possible) hack to take advantage of the noise of 802.11x spectrum usage in big cities by using Other People's Networks to move network traffic between people who want to route between each other's networks - but can't see each other, because Other People are in the way, or at least, Other People's Networks are visible to both. I didn't get any pictures of Matt's presentation - which is a pity. Did anyone else? That's it!
Paul: I got the technical low-down on this one too. Quite honestly, I barely understood it but here goes anyway: the idea is to use the increasing number of open routers not to leech their HTTP access but, by hacking your own wifi driver at Layer 2, associate to multiple networks and employ some kind of multicast shenanigans that will be relayed 'under the radar' by the Other People's Networks. Neat idea; as yet unimplemented.
next dorkbot: wednesday 20th October 2004, state51, then the third wednesday of every month.
Cheers, Saul.
September 17, 2004
Netgear sucks
Posted in: TechFor at least half a decade I've really liked Netgear's line of hubs and switches. They have a pleasant deep blue colour, reassuringly solid metal case, and Just Work. I must've been quite taken with the quality of these products, or certainly the lack of bad experiences using them because it's only just dawned on me and with some reluctance, years later, that every single Netgear product I've used since then has sucked.
Our house network is a 1152kbps ADSL from Nildram connected to a Netgear DG834G 54Mbps ("G") wireless firewall gateway. My Windows XP Home PC upstairs picks up the connection through a Netgear MA-111 USB wireless dongle.
Thus the roundtrip network hardware is pure Netgear so on the face of it one might be forgiven for thinking that the chances of hardware incompatibility would be reduced. Something certainly is amiss though: the connection is lost more often than not after putting it in Standby, and attempts to get it back tend to fail. I have to suffer an excruciatingly annoying dialog when this happens: "One or more networks are available", clicking the balloon, then "OK" merely to have the same damn balloon appear.
Here's how I'm sure Netgear sucks: to correct this situation I either have to reboot the PC, or pull out the dongle and re-insert it, or (get this) power cycle the gateway. That's right, turning the gateway on and off sorts the wireless problem with no further interaction with the PC!
Gah!
More personal experience of Netgear suckiness: bought an FA-311 NIC back in '01 and never successfully had it install on Windows 2000. Eventually returned it to the ever-reluctant CompUSA (loathe those f*ckers). This guy says it perfectly: "I recently bought this card by mistake".
Then more recently picked up a Netgear wireless PCI card. Now, I'm not absolutely sure but have a strong suspicion that the reason the machine it went into is hanging is down to the card. It was fine before (honest, guv'nor!) and the hangs only seem to happen during long downloads.
You can search for more evidence (I know this is self-fulfilling but you get the idea).
September 16, 2004
First rule of data-centre visits
Posted in: TechIt's quite simple:
However long you think it'll take, multiply that by about five
...and you'll get a considerably more realistic view of how long you'll be freezing your ass off and accumulating ear damage thanks to the aircon and army of fans, discs, and blowers.
Case in point: sshd was dropping incoming connections on one of my servers for some reason. Putting aside the mind-dissolvingly tedious 1hr10 trip across town (and back) it should've taken about 30mins. It took a little over 2h30. Not because it took a long time to restart a service but something(s) consumed those other two hours. At a more cosmic level the underlying reason isn't that important, except to be sure that it'll take about five times longer than you imagined. God help you if you think you have a two hour job on your hands; I've had server moves take literally entire days.
I can only think of one visit to a data centre out of dozens that took even remotely what I had expected, and even that was accompanied by an insanely high time-to-get-there : time-inside-data-centre. (Dec 2000, Monterey to Santa Cruz and back to reboot a machine and replace an initial # in a start-up file...).
September 9, 2004
Acrobat Reader tips & tweaks
Posted in: TechVia an intra-office circular via Nik these handy tweaks to having Acrobat Reader behave better. Both of our edits included.
In C:\Program Files\Adobe\Acrobat 6.0\Reader:Find the "plug_ins" folder and rename it something like plug_ins_disabled".
Create a new folder named "plug_ins".
Copy the following files from "plug_ins_disabled" to "plug_ins":
EWH32.api, printme.api, and search.apiIt will now load almost instantly.
Now that it's loaded, Edit > Preferences
General: Enable text selection for Hand tool
Internet: Display PDF in browser - er, that would be no, thanks
Startup: Display Splash screen? Also hell no.
Likewise Show Messages (which cancels the annoying rotating pastel ads in the top-right of the toolbar).
Units: I don't like inches. You might not either.
I've really come to dislike having PDFs display in the browser and I'm really glad it's possible to switch it off. In Firefox the plugins seem to haphazardly take over the browser's key-binding, e.g. Ctrl-K and Ctrl-T, two extremely useful keystrokes that are grabbed by Adobe Reader. And now they're back, woo hoo!
August 26, 2004
Lost headset
Posted in: Drivel, TechIf your Bluetooth phone headset went missing in a pub, what could you do to get it back?
The setting: around 21:00 with a couple of girlfriends trying to get into Cheers! on Piccadilly severely under-dressed (I'd come straight from an ultra-casual on-site coding job). Just for the record, both of them were looking quite spiffy. At first I thought the bouncer was objecting to my HBH-200 headset which was wrapped around my shoulders; it was looking kinda tatty. So I started taking it off, when it turned out the rip in my t-shirt was the problem.
At this point one of the girls offered me her jacket which I comically wore (she's about a size -6), she dragged me in past the dude in the blur, and we ordered drinks. Then I noticed my headset was gone. Heading back to the door both guys were bizarrely polite and empathetic "honestly we didn't see anything". Ehhh.
Anyway, I thought how could I use the technology to get it back. I'm sad to say I didn't pull it off but here's what I tried:
First off I did a device discovery. My Orange M1000 often presents Bluetooth "MAC" (proper term?) addresses rather than their human-readable ID. Now, I didn't remember what my headset's is so couldn't be sure the phone'd found it.
Next idea was to call my phone with the bluetooth headset enabled and hope that it picked it up. Even if I didn't hear the device the phone would report a transfer to headset. No signal in the back of the bar, so I borrowed Aini's phone and reasonably surreptitiously went out front near the boys on the door. No lock, nor device discovery. (I think, stupidly, I'd switched the headset off in the movie just beforehand. There is no need to do this: just silence the phone as no other phone will make it ring.)
So some lessons, besides obviously paying attention stashing gadgets. Make a note of the device's MAC address. Never switch if off. Develop a utility that will run on the phone to "call" the headset without needing an incoming call. Thinking about this, this is a really obvious one and I'm (now, having thought of it ;-) a little surprised phone's don't offer this feature themselves. Develop an app that continously discovers devices and reports on the signal strength (if this is possible). I'm sure something like that is out there, e.g. Bluestumbler.
August 22, 2004
Turning off PHP in a hurry
Posted in: TechHanging out at the Morpeth Mansions on Sat night, enjoying a gin & tonics session, descending deliciously into a quinine-flavored giggly haze, ... whereupon with little warning Rob & DC, a couple of playful computer security experts, instigated a "capture the flag" session with my production server. This involved attempting to get root on my box (i.e. total control) before I patched any holes they might've found...
The easiest target was the free upload service I run. This enables anyone to transfer a file through a couldn't-be-simpler browser interface and then be presented with a URL to that file. For times when you're stuck at a internet cafe or don't have an SFTP client it's fabulously convenient. I provide it as a service to folks I host as well: they can drop files directly into a safe area of their site wherever there's an internet connection. (For administrative information, the webmaster also gets notified over email of the upload.)
The upshot of this is that anyone can put files onto the system. Now, anyone in security is probably suffering major facial contortions at the thought of the implications to server safety of this.
Security balance
Security is all about compromise, a compromise between restriction of access and benefit to users. The most secure system is an unplugged one, but that's not particularly useful except to prop a door open. At the other extreme, a system completely without passwords is easy to use but concomitantly easy to abuse.
The upload service is extremely useful when it's needed. So for that I have to think hard about a way of providing it while minimizing the risk of server damage. What I've done to reduce chances of someone being able to cause mischief:
- the upload script has taint checking on to ensure every piece of data that comes into the script is filtered somehow
- path separators (/, \, :) are stripped from incoming file names (so amongst others ../ abuse isn't possible)
- non-letters and non-periods are replaced with underscores for clear names and additional filename safety
- some extensions are banned (right now, just rar files mostly since this is almost certainly a warez abuse)
- maximum file size upload (with password override)
- CGI execute permissions are switched off (-ExecCGI) so executable files are harmless. Files land up on the server without the execute bit set too. (The upload script itself has an explicit <Location> directive to allow it to be executed)
- and the upload script is not writable by the webserver process.
But... PHP
DC immediately tested to see whether PHP would be executed. What's different about PHP is that neither ExecCGI nor filesystem execute permissions need be on for Apache to go ahead and execute it. And sure enough, a hacked up phpinfo.php file ran. So I needed to turn this off, ASAP.
My first attempt was to remove the PHP handler with RemoveHandler .php. This didn't work, probably due to my misunderstanding exactly the implications of "handlers" and "types" in Apache.
PHP Shell
While I set about my task of disabling PHP, DC had uploaded the devious PhpShell utility. This provides and simulates a shell (using PHP's proc_open() call) through a web interface. Now this piece of software ought to give sysadmins the pause for thought: anyone hosting PHP in a shared server environment is opening up convenient access to at least the filesystem, possibly arbitrary program execution depending on the server's safe_mode setting. I believe the defaults are a permissive "off" for all the various safe modes.
So the race to capture the flag was on: could DC & Rob find a local root exploit before I figured out how to turn PHP off for that site? (Obviously, since I have such excellent PHP sites as Nik's online travelog diary running I couldn't switch PHP off globally.)
Root?
With shell access, the next step is attempting that local root exploit. DC tried the mremap_pte exploit for the do_mremap vulnerablility. Fortunately I'd heard about that and upgraded my kernel to 2.4.25 a while back so wasn't vulnerable. Phew!
How to turn PHP off
By this point (and he was working fast) I'd found a way of turning off PHP: php_flag engine off which works inside a virtual host. After restarting apache PHP was indeed off. Phew again!
The relevant parts of the httpd.conf are:
<Directory /home/www/paulm/html/paulm.com/tmp>
Options Indexes +FollowSymLinks -ExecCGI
DirectoryIndex index.cgi
php_flag engine off
</Directory>
<Location /index.cgi>
Options +ExecCGI
</Location>
Further remedies
I'm investigating with users how much safe mode I can switch on. I'd also like a way to automatically delete files after they've been downloaded a set number of times to prevent essentially warez abuse. (It's happened before, and I hope to write that up as it's quite a funny story how I arrived at a solution...)
If anyone would like a copy of the upload script to audit let me know.
Any other safety thoughts?
And finally...
Gin-fuelled penetration testing: fun & educational ;-) Cheers guys!
July 9, 2004
Urban Tapestries Slashdotted
Posted in: TechThe Urban Tapestries social research project into collaborative location annotation (phew!) was recently featured in Slashdot. A well-known side-effect of appearing on that enormously-widely read site is that the linked-to sites get pounded. It's not uncommon for those featured sites to go offline under the weight of Slashdot readers: hence "slashdotted".
Guess what happened?
Well, I'm delighted to report the whole show (physical server I specced, built, configured, installed, adminster, and the client-facing part of the software) stood up to the beating just fine.
Not only that, I was chatting yesterday with Giles at Proboscis who produce Urban Tapestries and there have been no technical queries or issues reported during a month-long 50-person trial that's taken place over the last month. I've presided over far more demanding jobs before but it's still nice when something Just Works, a phenomenon that most people who've used a computer have experienced as rare in software...
I'll sit here and glow with pride for a little while longer ;-)
June 14, 2004
Last.FM Downtime & tweak
Posted in: Drivel, Music, TechGah.. my favorite Internet radio station is down for some maintenance. The problem is that you then have to repeatedly go back and do a browser "refresh" to check if it's up again (gotta have them tunes!). So I mailed Felix there and suggested they put in an automatic refresh on the webpage and change the page <title> so "Downtime" appears early in the browser/taskbar/tab. That way a casual glance will reveal when Last.FM's back up. (It's these kinds of attention to detail that really make a site. Last.FM is full of them.)
Fifteen minutes later he'd implemented it. How cool is that?

June 6, 2004
C64 Audio
Posted in: Art, Music, Old Skool, TechJust got back from NotCon '04 and was curious about what had been left behind on its host site, xcom2002.com: a website pretty much covered in cobwebs, last updated around early 2003. Skimming down the page I saw a link to C64audio.com and, being a huge fan of C64 audio back in the day (mid-late 80s), went exploring...
Somewhere down on c64audio.com is a link to the High Voltage SID Collection, the C64/SID tune archive. Mind-boggling tens of thousands of SID tunes.
What is the SID? It is the dedicated 3-voice polyphonic Sound Interface Device in the C64. Voted alongside the Pentium and Sun SPARC as a Top 20 of All Time Computer Chips: "In 1981, Bob Yannes was told to design a low-cost sound chip for the upcoming Commodore 64. He would end up creating an analog synthesizer chip that redefined the concept of sound in personal computers." What the composers and programmers ended up doing with the SID and 1MHz 6510 defied comprehension; the soundtracks of games were often works of art in their own right.
To get the C64 audio experience, I: downloaded WinRAR to unpack the "Complete HSVC 5.7" (.rar is smaller) , and finally to play it grabbed sidplay2, the recommended player. Since I have an Audigy soundcard I diligently spotted they have a SID Live! Experience (see "SID Tools" section below HVSC tools) to tweak around using the Audigy's Environmental Audio features (couldn't get this f*cker to work). There's even a winamp plugin to upload SID files to and control your C64 via a serial cable. Mental.
So, installed WinRAR, peeled open the massive rarchive, and went immediately hunting for Martin Galway (the HVSC is organised primarily by composer, Galway_Martin style). Fired up sidplay2, dragdropped arkanoid.sid onto it. Whooooo!!!! Oh, man, I am 15 again.
Definitely check the voted Top 100 SIDs especially to get started and get a feel for the popular composers Rob Hubbard, Ben Daglish, Martin Galway, Jeroen Tel (Maniacs of Noise), all whom were regarded by some of us as gods. Sidplay2 has quite a decent file/dir navigator under View->Directory-based UI (Alt+D).
Listening to Hawkeye's (screenshots, loader) game tune and loader riff is bringing me out in a cold sweat. In 1988 on my French exchange visit, I read, re-read, re-re-read, indeed learnt the damn thing "par coeur", the Zzap64! review of that truly jaw-dropping game–3weeks of waiting to get back to the UK to get this creation that every mag reviewer was salivating over. One of the few games I actually paid for :-) Ahhh, heady teenage emotions....
This journey has also had the satisfying side-effect of allowing me closure on a long-standing (six-year!) itch. Just how similar is the opening sample of BMX Kidz and Coldcut's Timber? Really goddam similar. (Click the green preview button on last.fm, and use sidplay to play the .sid)
Want more? Great collection of links to C64 sites.