October 29, 2006
Converting Movable Type URLs
Posted in: Movable Type, Software, TechBack in Aug of 2004, I switched my blog to use descriptive URLs rather than the old-style, Movable Type 2 default of /archive/002981.html.
The downside to this is that after the site rebuild I had effectively created a whole 'nother blog, one all crosslinked in the new style, and one in the old style. And because the rest of my site has random links into the old style from before the change it continues to be crawled. To this day I still get search referrals pointing to the old site.
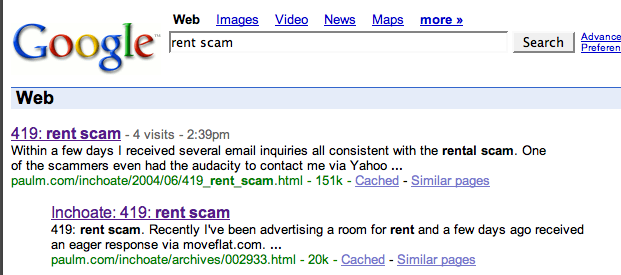
This isn't so bad except for two things. Comments go to the new site, not the new one. So referrals where someone's looking for rent scam help would, on the old site, miss out on all the useful (and entertaining in some cases) comments. The other bad thing is that the old site isn't running ads. OK, you might think that's a good thing :-)
So tonight I decided to fix this. Here's how I did it.
Overview: Redirect!
The strategy I took was to produce a set of redirects from the old site to the new site. The best way to do a redirect is at the webserver level as it teaches crawlers and browsers where the new pages are. There are in fact two types of redirects, temporary (aka "302") and permanent (aka "301"). Apart from being correct, the latter is also the preferred-by-search-engines method--tales abound of sites losing PageRank for using 302 temporaries.
Using the Apache webserver, I needed to produce a whole pile of RedirectPermanent directives to be included in paulm.com's Apache configuration.
MT code to the rescue
For this I need to get a list of all my blog's entries and create URLs for their new version. I can create the old one easily as the URL is the blog entry's internal ID, zero-padded out to six digits. To create the new URL I had to dig around a little in MT's guts and call MT code directly.Here's the answer,
export PERL5LIB=/home/mt/cgi-bin/lib
perl -MMT -MMT::Blog -le '
$mt = MT->new(Config=>"/home/mt/cgi-bin/mt-config.cgi");
$b = MT::Blog->load(13);
@e = MT::Entry->load({blog_id=>13});
for $e (@e) {
printf "RedirectPermanent /inchoate/archives/%06d.html %s\n", $e->id, $e->archive_url;
}' > /etc/apache2/paulm.com-redirect.conf
OK, what's going on here. First we need to create an instance of the top-level MT object. (Here we see an awesome example of how to abuse Perl's object model--subsequent object instantiations, e.g. MT::Blog make no reference at all to that MT instance, it all just magically works. Ah, pixie dust.)
Next up we load up my blog object. I know its id is 13 by looking in the mt.cgi URL: blog_id=13. Alternatively you can look in the mt_blog database table. I don't actually need this line of code as it turns out I can pull the blog entries out directly. I decided to leave this line in there for some extra documentation and reference.
So the load() method works with several MT types, the ones sublcassed from MT::Object, and has a fairly rich interface. This example shows loading all the entries of blog_id 13. Reassuring when I print scalar(@e) I got 336 which is the same number as reported on my blog dashboard page.
After divining that MT::Entry::archive_url was the right method for printing an entry's URL the ball's in the net. The final piece was manually constructing the old-style URL using printf "%06d" which says "print this decimal zero-padded to six digits".
Now in my /etc/apache2/sites-available/paulm.com I simply added,
Include /etc/apache2/paulm.com-redirect.conf
and kicked the webserver,
apache2ctl config && apache2ctl graceful
(&& is an improvement on ; in that it'll only execute the next command if the first succeeded.)
Finally I of course needed to test it worked, paulm.com/inchoate/archives/002950.html. Yep!
And in the logs,
perl -lane 'print if $F[8] == 301 and $F[6] =~ /\d{6}/' /var/log/apache2/paulm.com-access.log
x.x.x.x - - [29/Oct/2006:23:46:20 +0000] "GET /inchoate/archives/002919.html HTTP/1.1" 301 279 "-" "Mozilla/5.0 (Macintosh; U; PPC Mac OS X Mach-O; en-US; rv:1.8.0.7) Gecko/20060909 Firefox/1.5.0.7"
Do I need all those redirects?
Now, the exceedingly smart and observant reader will note that I haven't used the old-style URL for two years. So two years' worth of blogs aren't written out to the disk in that old format and that means two years' worth of 301 redirects I don't need to have Apache consider. So I'm going to clear them out of thepaulm.com-redirect.conf. One option might be to re-run the script above and put the date as a constraint in the MT::Entry->load() call. This would require me to figure out how to do that and, being lazy, I just can't be bothered (if you know, feel free to leave a comment). So I'm going to throw my sys-admin skills at the job instead.
But... I can feel a two-in-one trickshot coming on. But to set up this trickshot, another observation:
I still have "two" blogs. I need to remove those old pages. It would be easy to just go ahead and wipe them out with rm inchoate/archives/00*.html but I'm curious to see if anything's left after I remove only we know about.
Can you see the trickshot? I'm going to remove the unnecessary redirects and at the same time remove the old files, all in a one-liner. So, I re-used the results of the last bit of code (redirect.conf) pulling out the old-style URLs (/inchoate/archives/002918.html) and turning them into their place on the filesystem. Now I can test to see if they exist and if so, remove them and keep the redirect line, and if not, remove the redirect line.
perl -ani~ -e '-f ($f = "/home/www/paulm/paulm.com$F[1]") and unlink($f), print' /etc/apache2/paulm.com-redirect.conf
This scary bit of code does an in-place modification (-i) of the redirect file saving a copy with the ~ extension in case I make a mistake. I make use of the surprisingly little-used -a switch which splits the line into the @F array ('a' for 'awk' which by default has these in $1, $2, etc). So $F[1] is the old-style URL. If the file exists, the -f test, then unlink (remove) it and print the line. The effect of printing the line retains it from file.
So as an aside we see two perl one-liner idioms,
perl -ni~ e 'print if $some_condition' to remove lines except some and perl -pi~ -e 'do_something_with_each_line(); # typically an s///'
Back to the job: I want to observe what happens, so I take before and after shots with ls $paulm/inchoate/archives/00*.html; wc -l /etc/apache2/paulm.com-redirect.conf. I.e. take the before shot, run the above perl line, and re-run the ls; wc -l "after" shot. For the latter I get, reassuringly,
ls: /home/www/paulm/paulm.com/inchoate/archives/00*.html: No such file or directory
47 /etc/apache2/paulm.com-redirect.conf
Since this has changed my apache configs another webserver kick's needed.
And categories, monthly archives, RSS, and...?
It's all well changing the entries but what about the old-style archives/2004_08.html? Laziness prevailing here again I checked the last week's logs for references,
ls $paulm/inchoate/archives/200*_*.html # this revealed four from 2004, hence: grep archives/2004_0 $logs
Nothing. Delete 'em: rm $paulm/inchoate/archive/200*_*.html
The same wasn't true for categories unfortunately,
grep cat_ $logs
yielded one repeated result appearing. I traced this to a single blog entry which I manually edited and rebuilt. After that I deleted the
cat_*.html pages.
The old RSS feeds could go, rm $paulm/inchoate/archives/[0-9]*.xml $paulm/inchoate/[0-9]*.xml
Correcting old links
We're not done yet! I want to make sure the rest of my site isn't referring to the old pages. No harm would come of it if I left it as is but I'd rather finish the job, and it'll keep my logs clean too.My site's built from little XML fragments and full HTML pages, so I'm going to look in all of them and switch references to the old style,
find $paulm \( -name '*.html' -o -name '*.xml' \) | xargs grep -l 'inchoate/archives/00' | tee /tmp/old-style-pages
This returned a bunch of blog and non-blog (i.e. "home page") entries. The blog entries will require actually fixing the entry in the database, but I can fix the static files easily enough right now. I can also fix the blog files and they'll be fine until I do another rebuild.
There were tantalisingly few there (about four)--I was sorely tempted to hand-edit them. But no, see if I can whip out another one-liner in less time than it takes to look each one up:
</tmp/old-style-pages xargs perl -pi~ -MFile::Slurp=read_file -le '
BEGIN {
%h = map { (split)[1 => 2] } read_file("/etc/apache2/paulm.com-redirect.conf");
s~http://paulm.com~~ for values %h;
$re=join "|", map "(?:http://paulm.com)?$_", keys %h
};
s/($re)/$h{$1}/ge'
The neat trick here is that I'm doing an in-place file change while using the BEGIN clause to slurp in the redirect file and make a hash mapping the old style pages ("word" 1 of the line) to the new URL ("word" 2). Skipping the next line for a second I create a big regex to match any reference the old-style URLs.
Now those mystery references to http://paulm.com: This is quite subtle. The references in the script to my base URL http://paulm.com combine to remove that from the URLs in the pages. By not replacing with the full URL, the script also works on matches on filesystem references, e.g. /home/www/paulm/paulm.com/inchoate/archives/002918.html. Without it you'd end up with /home/www/paulm/paulm.comhttp://paulm.com/inchoate... (I didn't get this the first time round; only after I ran the script on one page and noticed it on a file that did an INCLUDE of a blog entry).
(By the way, if you're thinking, my god, who writes scripts like that off the top of his head? The answer is, if you're prepared to experiment, play, and believe it's possible: "you")
What next?
The test for success here is no 404s (missing pages), just 301s (permanent redirects). So over the next few days I'll be keeping an eye on my server logs using techniques shown above, and tail -f the error log in a window.
Moral
Changing one's URL scheme is not something to be undertaken lightly! However, if you do choose to, having a blogging engine that enables relatively straightforward construction of scripts and one-liners to manipulate its data renders the job a matter of a half-hour or so of reading docs and experimentation.
And of course behold the power of perl and unix to perform sophisticated data transformations and get the job done!
July 5, 2005
MT-Blacklist switch to mod_perl
Posted in: Movable TypeMT-Blacklist is dog slow even on a fast machine running as a standard CGI script with (in our case), 3,500+ entries. The time spent is parsing the YAML blacklist; here about 10s. This 10s pause is passed onto commentators who often bang the Submit button twice presumably, and quite reasonably, wondering WTF is happening.
MT-Blacklist isn't mod_perl friendly. I don't really understand people writing web apps in perl without expressly thinking "I need to write this as a mod_perl or even Apache::Registry app" but hey ho. I managed to get MT-BL mostly working under mod_perl by doing something quite sneaky, see below.
The problem is that this is old unsupported software so there's a question over the ongoing benefit in these hacks. Even MT-BL's author appears to be trialling life without MT-BL in favour of apparently excellent SpamLookup, an MT3 phenomenon (which incidently includes many features I'd done prototypes for last year - Brad Choate's gone beyond that even; cool!).
In summary, ongoing direction now is really down to hosted users.
How it works
[skip to the Where next? if tech ain't for you.]
The problem is that MT-BL uses CGI's HTML generation code as well as the usual query/POST parsing. Apache::Request does the latter in a drop-in stylee but not the former. So we need to intercept calls and see if A::R can do it, else pass over to CGI.
We make a stub class,
package paulm::Request;
use CGI;
sub AUTOLOAD {
my ($sub) = $AUTOLOAD =~ /.*::(.*)/;
return if $sub eq 'DESTROY';
if (Apache::Request->can($sub)) {
no strict 'refs';
&{"Apache::Request::$sub"}(@_);
} elsif (CGI->can($sub)) {
shift; CGI->$sub(@_);
} else {
die "Can't do $sub\n";
}
}
Then in blacklist.cgi a one-liner:
bless $app->{query}, 'paulm::Request' if $ENV{MOD_PERL};
There's more though: there's no benefit right now as the YAML is parsed per request. We need to do that in the Apache parent process so each child gets a copy. While we're at it, pull in various modules in the parent so they're preloaded and shared too.
<perl>
use lib qw(/home/mt/cgi-bin/lib /home/mt/cgi-bin/extlib);
use MT;
use Yaml; # MTBL's broken idea of what YAML is
use jayallen::Blacklist;
$jayallen::Blacklist::_cache->{blacklist} = jayallen::Blacklist::_getBlacklist();
</perl>
We're still not out of the woods yet. For reasons I haven't quite figured out (this was a quick hack after all), that internal blacklist array's first element is futzed with each request. The effect of this is devastating: Perl initiates a copy-on-write for the whole array blowing away the shared memory (although we still save on the initial load). Before long we have a half dozen Apache children scampering around with 30MB of RSS, each. Dammit!
Further, we need to add in some code to see if another process wrote to the blacklist, and if so reload it. Either that or do some IPC/shmem/Cache::Cache/etc tricks. At this point it's feeling more than a quick cheeky hack and more like a Real Project, which on senescent software is a questionable use of time.
Where next, then?
Next moves are properly investigating MT3; other blog software; getting MT-BL to serialise its BL (I think it oughta--no idea how?); or back porting some of SpamLookup but I don't even know if the license permits it (not to particularly worry, I've already written a load of DNSBL code and even run a DNSBL). I think I'll let the users decide...
Upsides is I know even more about the MT code-base, fixed a couple of my minor misconceptions about mod_perl, have my own MT2 running under mod_perl which is really nice, and I had the chance to write a brief flash of non-boring perl :) It's the little things in life...
June 29, 2005
Movable Type Maximum System Load
Posted in: Movable TypeHad the mother of all comment spam attacks today lasting several hours, and having had the machine crippled for most of that time (loads in excess of 160!) I at last resolved to do something about it: implement a MaxSystemLoad setting for Movable Type.
It was surprisingly straightforward, testimony to the reasonable clarity of the MT codebase. A call to Sys::Load to get the 1-minute load average, and a die during the early checks in MT::App->run if the MaxSystemLoad is exceeded. Easy.
Here's a patch: mt_maxsystemload.patch. This is against my own hacked 2.66x distro but ought to take against stock 2.66x.
Enjoy...
PS I'm going to watch to see what happens with this and consider putting a sleep 10; just before the die to tie up the spammers a while.
PPS Cunning how the spammers picked a time when I was having xrays in hospital and couldn't get SMS or GPRS to take action?
November 9, 2004
Comment spam new direction
Posted in: Movable TypeEveryone knows about MT-Blacklist but there are some problems with it. This entry is a quick jot for an idea I had actually last year for re-using technology that's proving successful with rejecting mail spam: focussing specifically on identifying URIs of spammers, rather than looking at the whole comment/message body.
Before that I should preface this with the disclaimer that I only use the 1.x series for my own hacked MT2.66. I should also disclaim that I'm barrelling this entry out before heading to the pub so it's not as linked-up or researched as I'd like. So, onward:
MT-Blacklist works by scanning a huge list of search queries ("blacklist") against incoming comments. The problem with this is that it's slow. Simply firing up mt-blacklist.cgi on this 1.8GHz server requires over ten seconds. The other problem is managing the blacklist: everyone running MTBL has their own copy, and a lot of the code in MTBL is aimed at managing this list.
How do the mail spam guys solve this? They identify links in the spam body and compare those against a list, essentially asking "is this website linked to a spammer?" The neat thing is that DNS supports this very easily. Such a system exists now at SURBL, the Spam URI Realtime Blocklist.
So the idea is simply this: produce a blocklist and supporting software that contains a list of URIs that are appearing in comment spam.
The additional bits of software required are some method of reporting a URI and then entering it into the DNS. The SURBL guys solved this by using the SpamCop feed (link?). Something similar needs to be produced for comment spam since the overlap from mail spamming to comment spamming is apparently not as large as you might expect (reference?). That's to say, using the existing SURBL data for identifying comment spam isn't that effective.
One interesting idea I'm not sure if it's being used is to watch the nameserver query statistics to "pre-report" comment spams. My experience running MT for a few sites is that the comment spamming comes in vast, crushing waves that create load spikes. The system could then auto-list URIs for moderation (rather than outright blocking). I suspect this would be quite effective.
I actually have the apparatus here having developed such a system. When I get a moment I might play with it.
Coincidently, today Brad Choate's tackled a similar problem by porting a Wordpress plugin that identifies open proxies used for spamming, MT-DSBL.
November 4, 2004
Date format in Movable Type
Posted in: Movable TypeMT 2.66's default time format of "04:36 PM" is just wrong, wrong, wrong. Even a crappy digital watch doesn't add a zero to a 12-hour clock. That whole AM/PM thing is kinda last century too (sorry, America).
Fortunately it's easy enough to correct.
* Head to Templates
* Edit Main Index and search for Date to find MTArchiveDate
* wherever there's a reference to format="%X" (not "%x"!) or "%I:%M %p" replace it with "%H:%M"
* Click Save (no rebuild yet)
* Back to Templates
* Repeat for Category Archive, Date-Based Archive, Individual Entry Archive
* Repeat for the Individual Entry Archive, Comment Listing Template, and Comment Preview Template looking instead for MTCommentDate: add format="%B %e, %Y %H:%M" to make <$MTCommentDate format="%B %e, %Y %H:%M"$>
* Repeat last step searching for MTPingDate in the TrackBack Listing Template
* Click Save each time of course
* Now, Rebuild All
It's a shame there isn't a way (I'm aware of) to set the date format overall rather than a pile of fiddly changes.
The documentation itself is wrong saying "%X" is "The language-aware time representation. For most languages, this is just the same as %I:%M %p. Example: 4:31 PM." but %I is actually the zero-padded 12h format aberration.
October 4, 2004
Movable Type URL redirection
Posted in: Movable TypeMovable Type 2.661 has a "feature" that shrouds an author's URL behind a redirect in the hopes of reducing the google-juicing effect of comment spammers being linked to during their nefarious activities.
There are several problems with this, see this excellent breakdown. Most importantly, any halfway competent MT installation will have some software to manage the comment spam, like MT-Blacklist. So the whole annoying redirect "feature" is redundant when you have no comment spam.
But there's no way to turn it off in 2.661, and I haven't found a patch for it, so I have just written one which also corrects a few bugs I found in MT::Template::Context.
Features:
* Turns off URL redirection by default (do a Rebuild to pick up changes)
* To turn it back on add the redirect_url="1" to MTCommentAuthorLink and MTEntryAuthorLink references
* If you do want redirection, the anchor contains a title attribute so you can mouseover it and at least see where you're going
Fixes:
* Known bug in 2.661 (in fact due to the URL redirection!) where during a comment preview an error appears, MT::App::Comments=HASH(0xdeadbeef) Use of uninitialized value in sprintf at lib/MT/Template/Context.pm line 1187.
Here's the patch or complete lib/MT/Template/Context.pm file. If someone would like to contribute an updated mtmanual_tags.html I'll include it.
I was seriously tempted to make the show_email default to 0. You may like to do this. It's quite obvious where this is in the code.
If you wanna look leet, roll your installation's version number in MT.pm :-)
PS It's quite late at night and this code isn't heavily tested. Seems to work though...
August 1, 2004
Movable Type URL tweaks
Posted in: Movable TypeI've been having "URL envy" for some blogs where the title of the entry appears in some form in the URL. So instead of /archives/002996.html it's /archives/that_blog_about_foo.html. Not only is that form of URL more descriptive, it's easier for me to remember, and even assists search engines in indexing the site (in other words, for search terms including the words in the URL these pages will appear higher up the results). After poking around the ever-useful Elise MT site I found how to do it.
For the record here's what I used:
- Individual
<$MTArchiveDate format="%Y/%m"$>/<$MTEntryTitle dirify="1" trim_to="32"$>.html - Monthly
<$MTEntryDate format="%Y/%m/"$>index.html - Category
<$MTArchiveCategory dirify="1"$>/index.html
Additionally, in Website Config, I set the Archive URL and Local Archive Path to be the same as the Site URL and Local Site Path, i.e. remove the archives/ path. I did this since it's already archiving under a date-based URL.
So I now have http://paulm.com/inchoate/2004/07/damp_assassins.html rather than http://paulm.com/inchoate/archives/002996.html, and referencing categories is as simple as http://paulm.com/inchoate/events/ -- much better!
Incidently, the reason for 32 in the trim length above is that it's 72chars minus the number of characters in the rest of the URL http://paulm.com/inchoate/200x/yz/.html (counted using unix's wc -c of course :-). Having URLs 72chars or less makes them pretty safe for sending in email without some poorly designed software (i.e. Outlook) breaking the URL in half.
June 11, 2004
Movable Type Recent Comments
Posted in: Movable TypeIt struck me that without indication somewhere, that readers would never know when an older entry was commented on. Only the author would know since they get handy notifications from MT. You'd in effect have to look at every archived post and try to figure out what had been commented on. I.e. you wouldn't bother. The effect of this is that conversations on older entries would be only between the author and the tardy reader.
Here's my solution.
So, digging about found some code at elise.com. This was enough to get me going but I wasn't really happy with it as it sorts by entries (see MTEntries tag around everything). If I were going to do that I'd attempt to merge it into the Recent Entries section already there.
(In fact, I actually did but <MTIfNotEmpty tag="MTComments"> gave some kind of bizarre Perl error, possibly since it's a container tag?)
So...
<div class="sidetitle"> Recent Comments </div> <div class="side"> <MTComments lastn="5" sort_order="descend"> <MTCommentEntry> <$MTCommentAuthorLink show_email="0"$> wrote: <$MTCommentBody trim_to="35" remove_html="1" convert_breaks="0"$>...[<a href="<$MTEntryLink$>#<$MTCommentID$>">more</a>]<br /><br /> </MTCommentEntry> </MTComments> </div>
Notes:
- The MTCommentEntry tag to find out the associated MTEntryBlah info so in this case MTEntryLink would work.
- I have sort_order="descend" to show most recent at the top.
- show_email="0" - jeez, as HTML authors, don't ever put email online, mm'kay?
- The MT [Save], [Rebuild], [Rebuild] (no, really!), [View this page] button pressing is a real chore. I struggle to see how the MT pair let this UX horror through.
PS How do people translate chunks of HTML for display in a blog? I crafted this perl one-liner:
perl -pe 's/&/&/g; s/</</g; s/>/>/g' > /tmp/esc
(which amusingly I had to run through itself to show it here :-)
January 5, 2004
First post!
Posted in: Drivel, Movable TypeI host a bunch of Movable Type sites but in a "hands off" manner. The expectation is that users will fend for themselves, RTFM, use the paulm.com mt-users list and so on. On the other hand, I'm a sucker for helping people out. So to that end I have installed my own MT weblog so I can at least say I'm not completely clueless about it.
Of course, I had to set all the MT permissions for my account to 11 :-)